
深度分析国产龙芯新架构CPU:自主崛起 力拼英美
- 来源:驱动之家
- 作者:liyunfei
- 编辑:liyunfei
而令人担心的地方也有三个——
第一,当一级指令缓存发生缺失时,缺失的地址会送给缓存失效队列进行处理。引入缓存失效队列(学界通称为MSHR)来负责从下层存储器取出缺失的和即将使用的预取数据本是早已成为标准配置的做法,但龙芯的缓存失效队列却由一级指令缓存和一级数据缓存共享,并且这个失效队列仅有16项,意味着仅能存储16个失效请求。笔者预计龙芯此后的设计将会尝试将失效队列分离或是提高容量;
第二,从框架上看,GS464E的指令TLB部分距离国际水准仍有差距,Intel在Sandy Bridge微架构上就实现了144项四路组关联的一级指令TLB,AMD的Bulldozer也实现了72项全相连一级指令TLB和512项四路组关联TLB的搭配,而龙芯仅有64项全相连一级指令TLB(一级指令TLB的大小较难提升),且并未出现二级指令TLB的设计,指令TLB覆盖范围的弱势可能会加剧指令缓存缺失之后的性能损失;
第三,IBM Power7的一级指令缓存部分与龙芯颇为相似,但是加入了先行路选择技术,推测性地只开启指令缓存中将要被访问的一个部分而不是全部,从而削减功耗,在此之外又非常激进地将一级指令缓存切分为16个bank,尽量避免读写冲突。而龙芯的指令缓存部分并未提及路预测技术的加入,也仅仅切分为4个bank。综合优势与劣势来看,尚不能简单断言龙芯的取指令效率能够比肩国际主流水准。

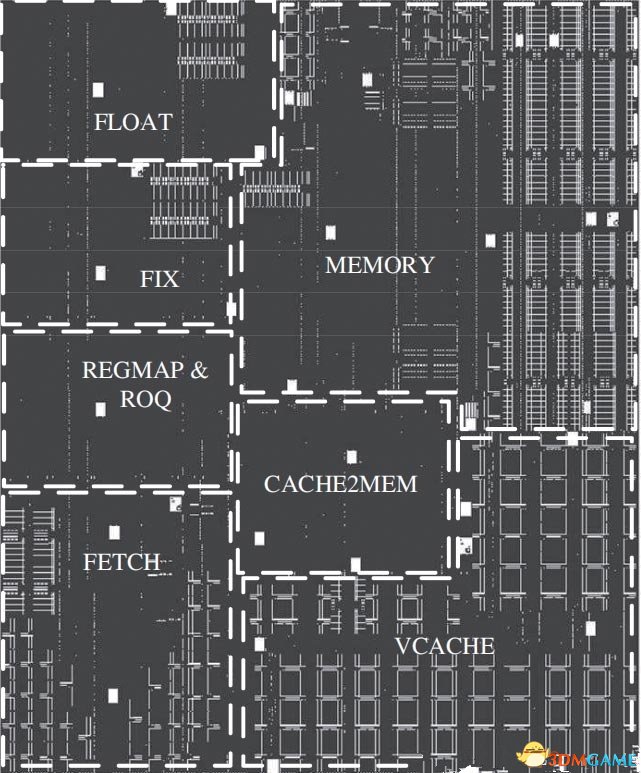
可以看到Victim Cache在GS464E处理器架构上占据了不小的空间
再来看前端中另一个不容忽视的模块—分支预测器。GS464E的分支预测器经过大幅改造,不难看出是投入了血本、大幅度提高了各项规格。从表面参数上来看,它已经能够比肩Sandy Bridge的水准—锦标赛分支预测器,返回地址栈,间接跳转预测器,一应俱全。
锦标赛分支预测器有三大主要内建部件—专门根据局部历史预测分支走向的局部历史表(Local Branch History Table),专门根据全局历史分支走向的全局历史表(Global Branch History Table),以及专门负责决断前两者哪一个准确率更高的全局选择表(GSEL)。三者的存储空间都达到了16K项的大小,推测与Sandy Bridge齐平,也超过了IBM Power7。
专门负责预测函数调用返回地址的返回地址栈(Return Address Stack)能够存储16项,与AMD Jaguar和IBM Power7齐平。在基本参数已经追平国际水准的情况下,比拼分支预测准确率的因素就落在了其他细节设计上,例如返回栈是否支持在错误预测下的栈修复、锦标赛预测器是否加入了其他设计技巧降低历史表的访问冲突等等。
笔者谨慎乐观地认为,只要这些细节设计不出现明显失误,GS464E的分支预测能力将可以与Intel的设计一决雌雄。
仍有落后 新一代GS464E之乱序执行引擎
尽管同为乱序四发射的框架,但从表1来看,GS464E的乱序执行引擎部分的基本参数相比Intel的Sandy Bridge仍有显著落后。
首先,重定序队列(Re-Order Buffer,ROB)决定了乱序执行引擎能够从多大的指令范围内抽取指令级并行度、挑选不相干指令进行乱序执行。而整数物理寄存器数量决定了最多容纳多少次整数寄存器重命名,在这些参数上龙芯仍有较大差距需要追赶。
除此之外,龙芯在发射队列上还是选择了设计难度较小、容易提高容量、但是也容易导致资源配置不均衡的分离式发射队列设计。AMD和MIPS历史上都曾使用过这种设计,在这种设计里面所有允许乱序执行的指令都是分类型分开存储的,比如整数指令存储在自己的独立发射队列中,浮点指令存储在另一个独立发射队列中,碰到整数密集型的程序把整数队列占满了之后,浮点发射队列可能是全空的。
与之相对的设计是集中式发射队列,集中式的发射队列设计复杂,极难大幅提高容量,但是所有的指令都存储在同一个地方,避免了空置的情况,这是与分布式发射队列不同的权衡。
在这种设计上,Intel已经浸淫多年,Intel的第一代乱序多发射微结构P6就是采用集中式发射队列,从Pentium4的Netburst开始改成了分布式发射队列,从Core开始又改回了集中式发射队列,并一直坚持至今,堪称是集中式发射队列设计的忠实拥簇。
在Core时代,Intel的集中式发射队列容量仅为32条指令,而AMD的K8所配备的分布式发射队列的总容量达到了60条指令,几乎多了一倍,但强大的Intel硬生生地将自己的发射队列容量逐年提高,终于在Haswell上实现了72条目的集中式发射队列和8发射端口的设计。在不存在并发条件限制的情况下,单单这一个集中式发射队列每周期就可以分派8条允许乱序执行的指令到各个执行单元,可谓是集中式发射队列的登峰造极之作。
龙芯在论文中并未透露自己的分派宽度,但从发射队列和执行单元的配置来看,笔者估计可能在4~6条指令之间。

当然,在具体的细节上,龙芯GS464E这一边的设计也有值得称道的部分。所有频繁触及的执行单元都能够单周期完成操作,并通过激进的数据前递设计在数据依赖的情况下支持背靠背发射,访存流水线支持访存指令的推测性发射和指令回放(一种较为困难的访存优化技巧,可以缩短访存延迟)。
更值得称赞的是,物理寄存器堆(PRF)和基于指针的发射队列处理逻辑也被早早地引入,这是一条曾经被Intel放弃的路线,后来为了引入AVX指令集又不得不选择相同做法,龙芯非常聪明地避开了Intel曾经走过的弯路。
但是这些细节改进并不足以帮助GS464E在乱序执行能力上叫板Core i7,龙芯需要再花费多长时间才能达到Haswell的乱序执行引擎的设计水平,就要看龙芯的物理和电路层设计水准能不能够撑得住规模更大的发射队列、更加复杂的数据前递网络以及支持更多并发读写口的物理寄存器堆,这些关键结构是支撑乱序执行引擎的设计重点所在。
容量充足 新一代GS464E之缓存系统
GS464E的一级数据缓存部分与指令缓存同为64KB,四路组关联,但是改成了串行访问设计,亦即先访问地址标记阵列(Tag Array),确定命中后再访问数据阵列(Data Array)。这种设计的意图是牺牲几个周期的访存延迟带来更低的访存功耗,但在GS464E可以维持4周期的一级数据缓存装载至使用(load-to-use)延迟的情况下,这个代价是可以接受的。
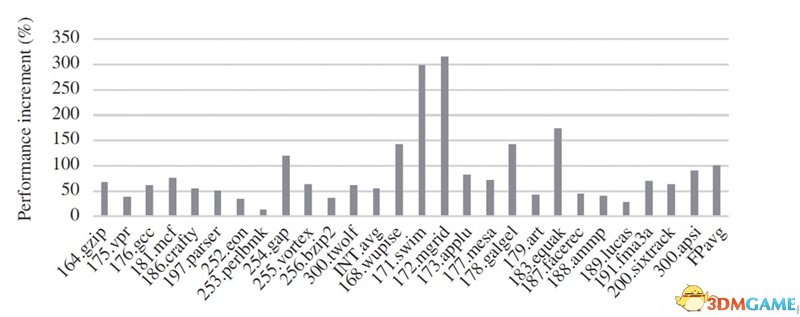
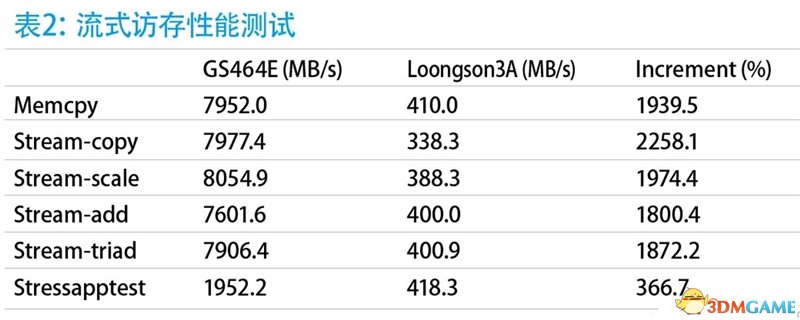
从更为可靠的SPEC CPU 2000测试来看,相对于上代龙芯3A,GS464E的处理器性能在一些子项测试中的提升幅度可达到最高300%以上。
比较有趣的是一级数据缓存之下的部分,每个GS464E核心在一级缓存下还有一道独立缓存系统,龙芯组将它称之为Victim Cache。
一般来说Victim Cache是附在一级缓存边的一个小Cache,仅能存储极少容量,主要为了接住被一级缓存踢出的数据,并在急需时快速传回它们。而龙芯的Victim Cache却有256KB,从术语约定上来说这就已经不是Victim Cache,而是正统的私有二级缓存。称呼它为Victim Cache的原因应该是因为这一道缓存与一级缓存之间是互斥式设计,亦即出现在一级缓存中的指令和数据在二级缓存一定没有备份。
作为参考,AMD也使用了相同的互斥式设计。而Intel和IBM则坚持包含式设计,亦即一级缓存中出现的内容在二级缓存中一定存在,这两种设计方式主要会影响到缓存命中率以及多核情况下的缓存一致性维护,各有优劣。
包含式设计的优点是简化了多核心计算下的同步问题,因为一级缓存中的数据保证在下层中存在,所以查询数据同步状态时只需要询问下层存储器即可,但缺点也非常明显,就是浪费了缓存空间,因为多层缓存都保存了多份同样的数据副本。而互斥式设计避免了空间浪费,但是每次处理多核心同步时都要检索整个多级缓存体系,让多核心的一致性问题变得更加复杂。
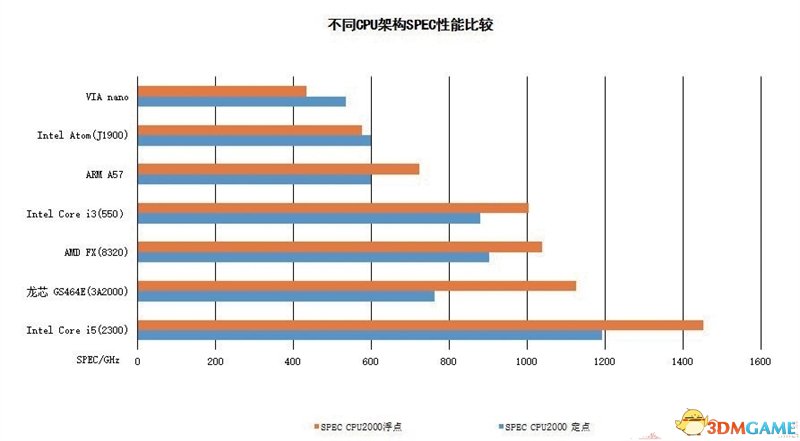
而从最新公开的测试数据来看,在同位1GHz频率下的环境里,GS464E架构的性能已经在浮点性能上超过AMD FX -8320,接近采用Sandy Bridge核心的Core i5 2300。
龙芯的二级缓存采用16路组相连设计,使用与一级数据缓存相同的串行访问模式,龙芯的论文中称这道缓存系统采用LRU替换算法,笔者认为这可能属于笔误,或者论文撰写者与缓存模块实际设计者双方出现了沟通不畅。
因为16路组关联如果要采用LRU替换算法就需要维持一个16!的状态数=20922789888000的状态机,这显然是无法实现的。历史上也从来没有超过四路组关联设计的缓存搭配了LRU替换策略,GS464E这里采用的应当是一个经过简化的伪LRU算法。
需要指出的是,采用伪LRU算法这并不是一个性能缺陷,好的伪LRU算法的替换准确率与LRU相差无几,在真LRU无法实现的情况下,所有超过四路组相连的缓存设计都是采用了伪LRU替换,Intel、AMD、IBM概莫能外。
在这个Victim Cache之下,还有最后一道被称为SCache的片上共享三级缓存,这一级缓存仍旧是16路组相连,每个SCache模块是1MB大小,四个核心的SCache模块拼接起来就是4MB。一般而言末级缓存系统都是切分多个Bank之后通过挂接到Crossbar上,各个独立核心通过Crossbar访问共享的末级缓存。龙芯将SCache直接挂接到GS464E核心外,可能说明龙芯已经采用了一些NoC(Network on Chip)的设计思路,在为未来扩展多核、众核做准备。
值得称道的是,龙芯的二级、三级两级缓存都维持了较大的容量和组关联度,但是访问延迟较长,二级缓存的访问延迟超过20个周期,比Intel处理器的二级缓存相比慢了几乎一倍,三级缓存需要超过50个时钟周期的时间,与Intel处理器基本持平。

























玩家点评 (0人参与,0条评论)
热门评论
全部评论