
新加坡中国联合团队AI新研究 输入文本直接生成虚拟形象
时间:2022-07-04 10:18:27
- 来源:外媒
- 作者:3DM编译
- 编辑:陶笛
来自新加坡与中国的联合团队日前公布了最新AI研究技术,可以通过输入文字文本直接生成对应的3D虚拟形象,引发业界热议,一起来了解下。

?目前的各种3D虚拟形象基本上都需要制作者有着丰富专业的图像处理技术,一般人难以企及,不过来自新加坡Nanyang Technological University与中国的SenseTime Research以及Shanghai AI Laboratory研究团队的新技术《AvatarCLIP: Zero-Shot Text-Driven Generation and Animation of 3D Avatars》则从根本上改变了这一现状,让没有任何专业知识的人群也可以轻松打造各种3D虚拟形象。
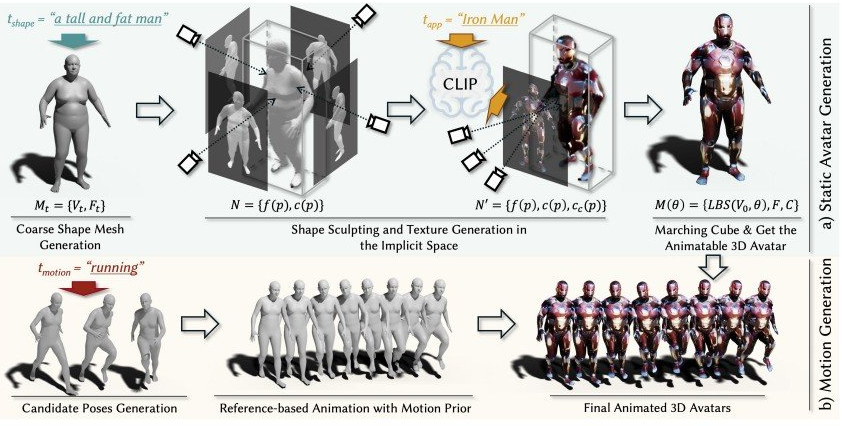
?比如示例之一的“I want to generate a tall and fat Iron Man that is running.”这段文本的意思就是需要制作一个正在奔跑的肥胖钢铁侠,或者“I would like to generate a skinny ninja that is raising arms.”,生成一位较瘦的举起手臂的忍者,诸如此类,通过文字文本直接生成对应的3D虚拟形象,当然如果你的描述更加细节的话距离你想要的目标形象就会更贴近。


























玩家点评 (0人参与,0条评论)
热门评论
全部评论